Identity Graph Linking Rules in a Multi-Brand Enterprise: A Real Implementation Story
By Stephen Tettey | Multi-Solutions Architect, Adobe Experience Platform and Adobe Journey Optimizer
Part 2 of 3 in the Identity Graph Linking Rules series
Part 1 of this series covered the mechanics of Identity Graph Linking Rules and a framework for deciding when to use them. If you have not read it, start there. This post assumes you understand how unique namespaces and namespace priority work.
This post is about a real implementation. It involves four brands operating on a shared Adobe Experience Platform sandbox, a profile collapse problem that ran deeper than any standard documentation example covers, twelve identity namespaces, a hard guardrail in AEP's linking rules configuration that most practitioners never encounter, and the process of building the evidence required to earn an exception to that guardrail directly from Adobe's engineering team.
This scenario does not appear in Adobe's documentation, official blog posts, or community forums in any meaningful detail. If you are working in a multi-brand or multi-entity environment and have started to suspect that the standard linking rules guidance is insufficient for your situation, this post is for you.
The Environment
Four brands. All subsidiaries of the same parent organization. All sharing a single AEP production sandbox. That setup created the conditions for one of the most complex identity collapse scenarios I have encountered in practice.
Each brand operated its own loyalty program. Members earned and redeemed points within their respective brand's program. Membership in one brand's program did not automatically create membership in another, but it was common for customers to belong to more than one brand's program or even all four. The same individual might have held a loyalty relationship with Brand A since 2015, joined Brand B's program in 2019, and carried accounts across all four brands by the time this implementation came under review.
Each brand also assigned its own participant ID at the point of enrollment. A participant ID was unique within a brand but carried no guarantee of uniqueness across brands. Each brand assigned its own loyalty number to members under the same condition: unique within the brand only.
Across all four brands, the parent organization maintained a shared CRM ID to recognize the same human across the entire portfolio. That was the one cross-brand anchor in the entire identity landscape.
Email addresses existed as profile attributes across all brands. They were not configured as identities at the time of the initial build. However, a critical business use case already on the roadmap required email to be elevated to an identity namespace for each brand. That requirement shaped the forward-looking architecture from the start.
How the Collapse Happened
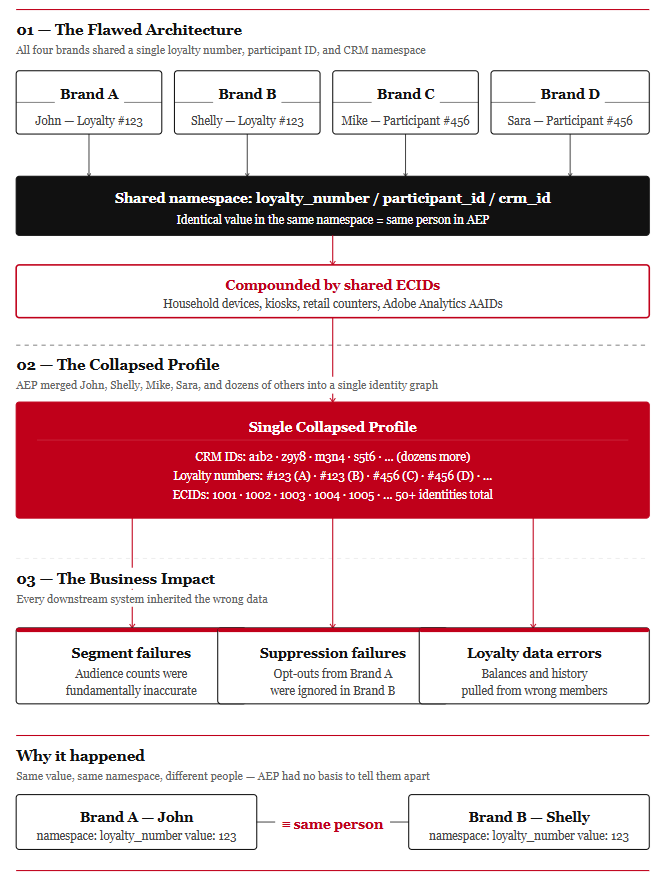
The initial AEP implementation was built with a single loyalty number namespace shared across all four brands, a single participant ID namespace shared across all four brands, and a single shared CRM ID namespace. On paper, this looked like a reasonable simplification. In practice, it was a systematic collapse mechanism.
The specific failure was this: loyalty number 123 in Brand A belonged to John. Loyalty number 123 in Brand B belonged to Shelly. Because both values were ingested under the same loyalty number namespace, AEP treated them as the same person. John and Shelly collapsed into one profile.
The same logic applied to participant IDs. A participant ID value internally generated by Brand A with no awareness of Brand B could produce the same numeric value as a participant ID generated independently by Brand B. Same namespace, same value, different people: instant collapse.
ECIDs compounded the damage significantly. Members were transacting across all four brand properties, frequently from shared household devices. Spouses sharing a laptop. Family members using the same tablet. Kiosks at retail locations used by hundreds of different customers over time. Each shared device produced an ECID that linked across authentication events. Because the person-level identifiers were already collapsing across brands, the ECID chains amplified the damage into multi-hop collapse chains connecting people who had no real-world relationship.
Adobe Analytics data contributed additional ECID and AAID values from web and mobile properties, each carrying its own device-sharing exposure.
The result was a production identity graph where a single collapsed profile could contain fifty or more identities. Not fifty identities belonging to one person with a rich multi-channel presence, but identities belonging to dozens of different real people stitched together through a chain of coincidental namespace value overlaps and shared device ECIDs.
The business impact was direct and severe. Segment membership was wrong. Journey suppression was unreliable. A customer who had opted out of Brand A communications was receiving Brand B communications because their opt-out profile was collapsed into a broader record that also contained active Brand B consent. Loyalty balance calculations were pulling from incorrect member records. Personalization across all four brands was operating on data that represented a fictional composite customer who did not exist.
Diagnosing Before Designing
Before proposing any solution, the team needed to fully understand the collapse topology. This meant systematically reconstructing the exact sequence of identity events that had produced the worst collapsed graphs in production.
We pulled profiles with the highest identity counts from the production environment and traced each one back through the ingestion history. We mapped which data sources had contributed which namespace values and in what order. We identified the specific namespace value overlaps that had acted as the initial collapse trigger in each case.
This diagnostic phase was not glamorous. It involved exporting profile data, writing queries against the data lake to trace ingestion sequencing, and building a written map of each collapse chain. But it was essential for two reasons.
First, it produced the full catalog of collapse scenarios that any proposed solution would need to be tested against. A solution that prevented future collapse but could not un-collapse existing graphs was only half a solution.
Second, it gave the team the evidence needed to demonstrate to the client that the existing architecture was fundamentally wrong and required a redesign rather than a patch. Clients do not easily accept the message that a production system needs to be rebuilt. Documented evidence of specific collapse chains, with named profiles and traced ingestion paths, made that conversation possible.
The Namespace Redesign
The governing principle of the redesign was straightforward: each brand-specific identifier needed its own namespace. A value that is unique only within a brand can only function as a unique identity if it is scoped to that brand at the namespace level.
Here is the full namespace architecture, with the final priority order.
Priority 1: CRM ID — Shared across all four brands. This was the one identifier that was genuinely unique across the entire customer portfolio. A CRM ID of 99001 meant the same person regardless of which brand's data carried it. This namespace was configured as unique and assigned the highest priority. Every other identity resolution decision flows from this anchor.
Priorities 2 through 5: Brand-specific loyalty number namespaces — One namespace per brand, named to clearly identify which brand it belonged to. The largest brand by membership volume received Priority 2, descending to Priority 5 for the smallest brand. Each was configured as unique within its own namespace. Loyalty number 123 in Brand A's namespace and loyalty number 123 in Brand B's namespace now referred to two completely separate identity constructs. AEP could no longer conflate them.
Priorities 6 through 9: Brand-specific participant ID namespaces — One namespace per brand using the same descending priority pattern from largest to smallest brand. Each configured as unique within its namespace.
Priorities 10 through 12 (reserved): Brand-specific email namespaces — At the time of the redesign, email addresses were profile attributes, not identities. But the known upcoming use case requiring email to be elevated to an identity namespace for each brand was incorporated into the architecture from the start. Building those namespace slots and their priority positions into the design in advance was a deliberate choice. Accommodating a known future requirement at design time is always cheaper than retrofitting it after data is in production.
That totals twelve distinct unique namespace configurations across the four brands.
The architecture was sound. The problem was that AEP's Identity Graph Linking Rules configuration enforces a hard limit of three unique namespaces.
The Guardrail Nobody Documents
This is the part of the story that every multi-brand AEP architect needs to know before committing to a namespace strategy.
As of the time of this implementation, AEP's identity settings enforce a maximum of three unique namespace designations within the Identity Graph Linking Rules configuration. For a single-brand or straightforward multi-channel implementation, three is sufficient. For an enterprise with four brands and brand-specific identifiers that must each be uniquely scoped, three is not close to sufficient.
This limitation is not prominently documented in the context of multi-brand implementations. It appears as a guardrail in the configuration UI and in the implementation guide in general terms. Most practitioners encounter it only at the moment they need to exceed it, after weeks of namespace design work.
Exceeding this limit requires engaging Adobe directly and requesting an exception. This is not a standard support ticket. It is an engineering-level review process. Adobe's product team must understand the specific use case, validate that the proposed configuration will not produce unintended consequences at scale, and approve the exception before it can be applied to your sandbox.
Earning the Exception
To make the case to Adobe's engineering team, we needed to accomplish two things: prove that the proposed twelve-namespace configuration solved the documented collapse scenarios, and prove that it did not introduce new problems in the process.
The simulation work happened in two phases.
In the first phase, we used Adobe's Graph Simulation tool to model every collapse scenario documented during the diagnostic phase. This included scenarios with more than fifty identities in a single graph, multi-hop collapse chains where the connection between two unrelated people ran through three or four intermediate namespace value coincidences, and shared device scenarios where a single ECID anchored loyalty members from two different brands who had independently used the same kiosk.
The Graph Simulation tool handled most scenarios well. But some of the most complex chains required a level of depth that the simulation tool alone could not fully validate. We rebuilt those scenarios in a lower environment by ingesting carefully constructed synthetic data that replicated the exact namespace values and ingestion sequences that had produced the worst production collapses.
In the second phase, we ran the same scenarios with the proposed twelve-namespace configuration applied and documented the before-and-after state of each graph. Every previously collapsed graph separated correctly into its constituent identities. No legitimate cross-brand links, meaning cases where the same human was correctly connected across brands through the shared CRM ID, were broken.
We compiled these results into a structured evidence document and presented it to Adobe's engineering team. The exception was granted only after the engineering team reviewed the simulation results and confirmed that the proposed configuration was technically sound and that the use case was genuinely outside the range the standard guardrail was designed to prevent.
The lesson here is not that Adobe's three-namespace limit is wrong. For most implementations it is a reasonable boundary. The lesson is that multi-brand enterprise architectures regularly produce requirements that exceed what the standard configuration was designed to accommodate. Know the guardrails before you commit to a design. And know that Adobe will engage seriously with a well-documented, evidence-backed exception request.
The Orphaned Identity Problem
Enabling the redesigned linking rules in the production sandbox did not simply re-sort collapsed profiles into clean separate graphs. It produced a third outcome that required its own handling: orphaned identities.
When a collapsed graph of fifty identities was broken apart by the linking rules, most identities found their correct home in one of the brand-specific graphs anchored by a CRM ID. But some identities had no CRM ID link and no high-priority namespace to anchor them. These became single-identity pseudonymous profiles: a profile fragment containing only an ECID with no authenticated person identifier attached, or a loyalty number fragment that had been part of a collapsed graph but now had no valid link to a CRM ID in the cleaned state.
These orphan profiles were not wrong. They were the accurate representation of identity data that genuinely lacked a person-level anchor. But at scale they created a large volume of low-value pseudonymous profiles that added noise to segment counts and consumed profile volume capacity.
The remedy was pseudonymous profile expiration, known in AEP as Pseudonymous Profile TTL. Profiles containing only non-person identifiers, such as a standalone ECID, that have not received any new event data within a configurable time window are automatically expired and removed from the profile store. Applying pseudonymous TTL after the linking rules were fully stabilized allowed the orphaned profiles to age out of the system without requiring manual remediation.
The trade-off is worth naming explicitly. Some of those orphaned profiles belonged to real people who had interacted with a brand property anonymously and had simply not authenticated during the TTL window. Those profiles and their associated behavioral history expired along with the genuine orphans. For this implementation, the business determined that the profile quality improvement from cleanup outweighed the loss of unanchored anonymous history. That calculation will differ by organization and should be evaluated explicitly before TTL is enabled.
What the Multi-Brand Pattern Requires to Work Correctly
Drawing from this implementation, here are the conditions that must be true for a tiered multi-brand namespace architecture to function correctly.
A single authoritative cross-brand person identifier must exist. The entire architecture depends on one identifier that is genuinely unique and shared across all brands for the same human. Without that anchor at the top of the priority stack, brand-specific namespaces float independently and cross-brand profile unification becomes impossible rather than simply difficult.
Brand-specific namespaces must be named and governed consistently. Each brand namespace must clearly identify which brand it belongs to and what kind of identifier it represents. These namespaces will exist in your AEP implementation for years. The team that configures them will not be the only team that works with them. Schema designers, data engineers, and analytics teams all need to be able to identify the correct namespace without ambiguity.
The redesign must account for anticipated future identifiers, not just current ones. Reserving priority positions for brand-specific email namespaces before email was an active identity proved its value when that use case arrived. Retrofitting priority ordering after the fact is possible but disruptive. Build for known future requirements at design time.
Plan for orphaned profiles before you enable the rules. Estimate the number of profiles that will become orphaned after un-collapse and confirm that pseudonymous TTL settings are configured and ready before you activate the rules in production. Discovering a large orphan population after the fact is manageable but avoidable with upfront planning.
A Note on Sandbox Architecture
The design described in this post solved the identity collapse problem for a shared sandbox. But it is worth stating directly: the cleaner long-term solution for four independent brands with separate loyalty programs and separate member populations is four separate sandboxes, or at minimum a development and staging structure where brand-level isolation is enforced before data reaches a shared production environment.
Consolidating multiple brands onto a single sandbox is a cost and organizational decision. It is sometimes the right decision, particularly when the parent organization derives genuine real-time value from analyzing how customers interact across brands simultaneously. But it should be a deliberate choice made with full awareness of the identity architecture complexity it creates, not a default inherited from an initial implementation that did not anticipate multi-brand scale.
There are also alternatives worth evaluating. If the goal is cross-brand insight rather than cross-brand real-time activation, Adobe Customer Journey Analytics can access, synthesize, and analyze data from multiple brand environments without requiring them to share a production sandbox. The analytical value is preserved. The identity complexity is contained within each brand's own environment.
Part 3 of this series, "Stop Resolving Identity in the Wrong Place," addresses the broader architectural question of where identity resolution should live in your stack and how sandbox strategy and identity strategy interact. The two decisions are more tightly coupled than most implementation teams recognize until they are already managing the consequences.
References
- Adobe Experience League: Identity Graph Linking Rules Overview — https://experienceleague.adobe.com/en/docs/experience-platform/identity/features/identity-graph-linking-rules/overview
- Adobe Experience League: Identity Settings UI — https://experienceleague.adobe.com/en/docs/experience-platform/identity/features/identity-graph-linking-rules/identity-settings-ui
- Adobe Experience League: Example Graph Configurations — https://experienceleague.adobe.com/en/docs/experience-platform/identity/features/identity-graph-linking-rules/example-configurations
- Adobe Experience League: Pseudonymous Profile Expiration — https://experienceleague.adobe.com/en/docs/experience-platform/profile/pseudonymous-profiles
- Adobe Experience League: Graph Simulation UI — https://experienceleague.adobe.com/en/docs/experience-platform/identity/features/identity-graph-linking-rules/graph-simulation
Stephen Tettey is an Adobe Certified Multi-Solutions Architect with five years of hands-on experience implementing AEP, Real-Time CDP, Adobe Journey Optimizer, Adobe Analytics, and Customer Journey Analytics across financial services, travel, loyalty, and cybersecurity industries.
Comments ()